loading
loading
loading
Click here - https://www.youtube.com/channel/UCd0U_xlQxdZynq09knDszXA?sub_confirmation=1 to get notifications. தமிழ் | EXPLAIN APACHE KAFKA EVENTS | ITS CHARACTERISTICS | EVENT PAYLOAD METADATA | InterviewDOT Apache Kafka, an open-source distributed event streaming platform, fundamentally revolves around events. These events, or messages, represent discrete pieces of data that capture occurrences or changes in a system. Here's a comprehensive look at Apache Kafka events: ### 1. **Definition of an Event:** - An event is a unit of data that represents a specific occurrence or action within a system. It encapsulates information relevant to the event's context, such as its type, timestamp, and payload. ### 2. **Characteristics of Events:** - **Immutable:** Once produced, an event cannot be altered or modified. Its content remains unchanged throughout its lifecycle. - **Atomic:** Each event is indivisible and self-contained, carrying all necessary data for processing without reliance on external context. - **Sequential:** Events maintain a strict ordering, ensuring that they are processed in the order of their occurrence. ### 3. **Components of an Event:** - **Key:** An optional identifier associated with the event, used for partitioning and message routing within Kafka topics. - **Value:** The payload or body of the event, containing the actual data or information relevant to the event. - **Timestamp:** Indicates the time at which the event occurred, facilitating chronological ordering and time-based processing. ### 4. **Event Production:** - Producers are responsible for generating events and publishing them to Kafka topics. They may originate from various sources such as applications, sensors, or external systems. - Events are serialized into a specific format (e.g., JSON, Avro) before being transmitted to Kafka, ensuring compatibility and interoperability. ### 5. **Event Consumption:** - Consumers subscribe to Kafka topics to receive and process events. They read events from partitions, maintaining their own offset to track their progress within each partition. - Consumers operate at varying levels of granularity, from individual events to batches of events, depending on the application's requirements. ### 6. **Event Streaming:** - Kafka enables real-time event streaming, allowing events to be processed as they are produced. This facilitates low-latency data processing and enables applications to react promptly to changing conditions. ### 7. **Event-Driven Architecture:** - Apache Kafka facilitates event-driven architecture, where systems communicate and react to events asynchronously. Events serve as the primary means of interaction between decoupled components, promoting scalability and flexibility. ### 8. **Event Sourcing:** - Event sourcing is a pattern where the state of a system is derived by applying events sequentially. Instead of storing current state, systems maintain a log of events that can be replayed to reconstruct state at any point in time. ### 9. **Event Serialization and Deserialization:** - Serialization converts events from their native format into a byte stream suitable for transmission over the network or storage in Kafka. - Deserialization reverses this process, reconstructing events from their serialized representation for consumption by applications. ### 10. **Use Cases for Events:** - **Log Aggregation:** Collecting and consolidating log events from distributed systems for centralized monitoring and analysis. - **Real-time Analytics:** Processing streaming events to derive insights and make data-driven decisions in real-time. - **Event Sourcing:** Building systems that reconstruct state from a log of events for auditability, replayability, and consistency. ### Conclusion: Apache Kafka events form the foundation of a scalable, fault-tolerant event streaming platform. By understanding the characteristics and principles of events, organizations can leverage Kafka to build robust, real-time data pipelines and event-driven applications.
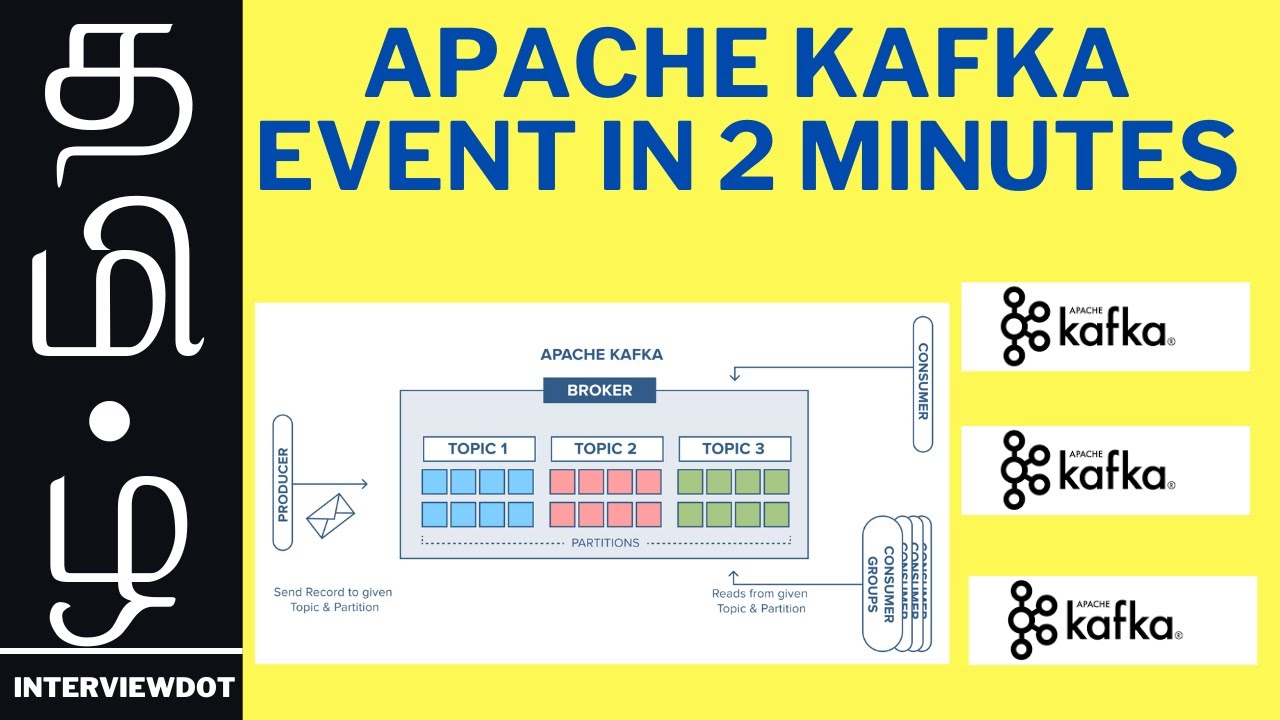
**Apache Kafka Messaging System in 4000 Characters:** **Introduction:** Apache Kafka is an open-source distributed streaming platform designed for building real-time data pipelines and streaming applications. Developed by the Apache Software Foundation, Kafka has become a cornerstone technology for organizations dealing with large-scale, real-time data processing. **Key Concepts:** 1. **Publish-Subscribe Model:** - Kafka follows a publish-subscribe model where producers publish messages to topics, and consumers subscribe to those topics to receive the messages. This decouples data producers and consumers, enabling scalable and flexible architectures. 2. **Topics and Partitions:** - Data is organized into topics, acting as logical channels for communication. Topics are divided into partitions, allowing parallel processing and scalability. Each partition is a linear, ordered sequence of messages. 3. **Brokers and Clusters:** - Kafka brokers form a cluster, ensuring fault tolerance and high availability. Brokers manage the storage and transmission of messages. Kafka clusters can scale horizontally by adding more brokers, enhancing both storage and processing capabilities. 4. **Producers and Consumers:** - Producers generate and send messages to Kafka topics, while consumers subscribe to topics and process the messages. This separation allows for the decoupling of data producers and consumers, supporting scalability and flexibility. 5. **Event Log:** - Kafka maintains an immutable, distributed log of records (messages). This log serves as a durable event store, allowing for the replay and reprocessing of events. Each message in the log has a unique offset. 6. **Scalability:** - Kafka's scalability is achieved through partitioning and distributed processing. Topics can be partitioned, and partitions can be distributed across multiple brokers, enabling horizontal scaling to handle large volumes of data. **Use Cases:** 1. **Real-time Data Streams:** - Kafka excels in handling and processing real-time data streams, making it suitable for use cases like monitoring, fraud detection, and analytics where timely insights are crucial. 2. **Log Aggregation:** - It serves as a powerful solution for aggregating and centralizing logs from various applications and services. Kafka's durability ensures that logs are reliably stored for analysis and troubleshooting. 3. **Messaging Backbone:** - Kafka acts as a robust and fault-tolerant messaging system, connecting different components of a distributed application. Its durability and reliability make it a reliable backbone for messaging. 4. **Event Sourcing:** - Kafka is often used in event sourcing architectures where changes to application state are captured as a sequence of events. This approach enables reconstruction of the application state at any point in time. 5. **Microservices Integration:** - Kafka facilitates communication between microservices in a distributed system. It provides a resilient and scalable mechanism for asynchronous communication, ensuring loose coupling between services. **Components:** 1. **ZooKeeper:** - Kafka relies on Apache ZooKeeper for distributed coordination, managing configuration, and electing leaders within the Kafka cluster. ZooKeeper ensures the stability and coordination of Kafka brokers. 2. **Producer API:** - Producers use Kafka's Producer API to publish messages to topics. The API supports asynchronous and synchronous message publishing, providing flexibility for different use cases. 3. **Consumer API:** - Consumers use Kafka's Consumer API to subscribe to topics and process messages. Consumer groups allow parallel processing and load balancing, ensuring efficient utilization of resources. 4. **Connect API:** - Kafka Connect enables the integration of Kafka with external systems. Connectors, available for various data sources and sinks, simplify the development of data pipelines between Kafka and other systems. 5. **Streams API:** - Kafka Streams API facilitates the development of stream processing applications directly within Kafka. It enables transformations and analytics on streaming data, supporting real-time processing scenarios. **Reliability and Durability:** 1. **Replication:** - Kafka ensures data durability through replication. Each partition has a leader and multiple followers, with data replicated across brokers. This replication mechanism ensures fault tolerance and data redundancy. 2. **Retention Policies:** - Kafka allows the configuration of retention policies for topics. This determines how long messages are retained in a topic. Retention policies support both real-time and historical data analysis. **Ecosystem and Integration:**